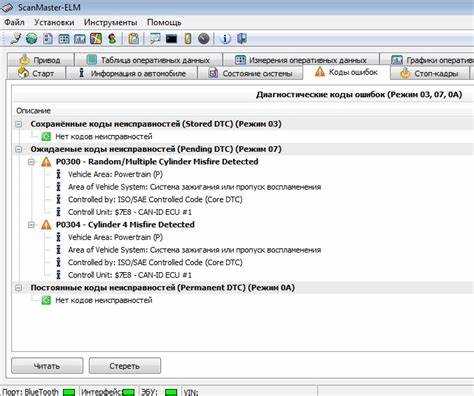
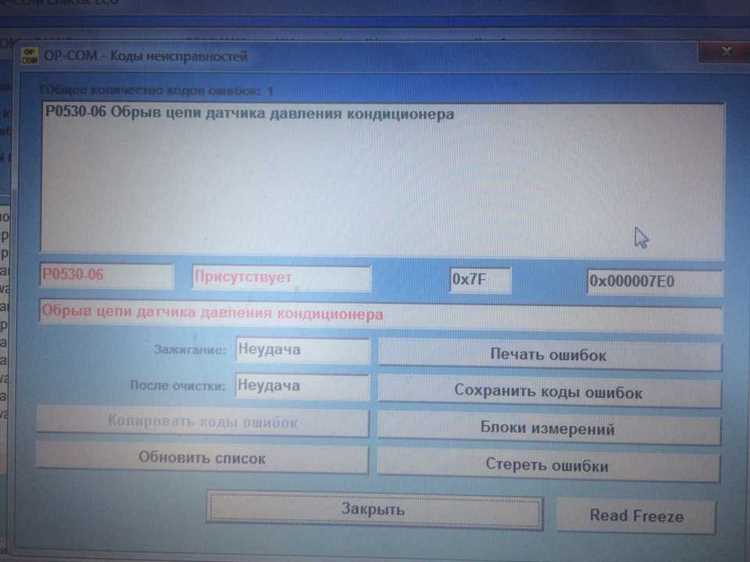
В последние годы стало очевидным, что корректность числовых значений в программных системах стала критически важной для обеспечения функционирования приложений. Неожиданные проблемы могут вызывать значительные сбои в работе, а их влияние распространено на множество других процессов. Особенно это касается ситуаций, когда неверные значения ведут к искажению данных и затрудняют взаимодействие между различными модулями программного обеспечения.
Проанализировав ситуацию, связанная с неверным значением в системе 2784, можно выявить множество направлений, требующих внимания. Например, сбои могут затронуть базы данных и привести к потере информации. Кроме того, нарушения в алгоритмах обработки данных могут способствовать возникновению дополнительных уязвимостей, что особенно важно в условиях роста киберугроз. Анализируемая проблема затрагивает, в том числе, и качество клиентского сервиса, что делает её ещё более актуальной для бизнеса.
Для предотвращения аналогичных ситуаций, рекомендуется внедрять строгие стандарты тестирования разработок на каждом этапе. Аудит кода и его рецензирование помогут выявить неочевидные погрешности до их появления в рабочем окружении. Также важным шагом является обучение разработчиков основам процессов обработки данных и их возможным последствиям, что повысит общую осведомлённость команды и снизит вероятность ошибок.
Причины возникновения сложности в вычислениях

Существуют несколько факторов, способствующих возникновению проблем в процессе обработки данных с использованием кода 4 в2784.
- Некорректные данные: Ошибочная информация в исходных файлах может приводить к сбоям на этапе вычислений. Проверка данных перед загрузкой является первостепенной задачей.
- Несоответствие форматов: Если данные представлены в разном формате, интеграция может оказаться невозможной. Рекомендуется стандартизировать формат данных, прежде чем начинать обработку.
- Ошибки в алгоритмах: Логические недочеты в программных алгоритмах могут вызывать недоступность результатов. Регулярные тесты и ревизия кода помогут минимизировать подобные ситуации.
- Неправильные настройки системы: Конфигурации программного обеспечения должны соответствовать требованиям обработки данных. Рекомендуется регулярно пересматривать настройки.
- Внешние воздействия: Параметры среды, такие как сетевые задержки или нестабильность серверов, могут негативно влиять на процесс. Поддержка надежной инфраструктуры поможет избежать этих проблем.
Анализ и устранение указанных факторов помогут повысить стабильность процессов и сократят вероятность возникновения трудностей в будущем.
Возможные признаки данной ошибки в системе
Другим сигналом может служить появление аномальных сообщений об ошибках. Частые и неожиданные уведомления о сбоях могут указывать на неустойчивость системы. Важно обращать внимание на детали этих сообщений, поскольку они могут содержать подсказки о сути проблемы.
Ненормальное поведение интерфейса также указывает на существующие проблемы. Например, отображение искаженных графиков, неправильная интерпретация данных и сбои в функционале. Эти визуальные проблемы часто свидетельствуют о внутренней сбалансированности.
Функции, работающие до этого без перебоев, могут стать недоступными или начать проявлять сбои. Это может затруднить выполнение привычных задач и вызвать затяжные процессы. Нужно обращать внимание на те элементы, которые стали работать с разной периодичностью.
Регулярные сбои в подключении к сети или другим системам также могут говорить о подверженности системе различным негативным факторам. Мониторинг сетевого трафика позволит выявить аномалии и понять, в чем заключается проблема.
Подозрительная активность в логах может являться ключом к выявлению проблемы. Необычные записи, частые входы из неизвестных IP-адресов или другие подозрительные действия требуют внимания. Анализ этих данных откроет новые грани текущей ситуации.
Наблюдение за изменениями в объеме используемых ресурсов системы также важно. Внезапные скачки нагрузки на ЦП, память или диск могут указывать на скрытые процессы, влияющие на стабильность.
При появлении нескольких из указанных признаков стоит провести диагностику системы. Регулярное тестирование и применение мониторинга помогут выявить и устранить подобные проблемы до их дальнейшего ухудшения.
Методы диагностики для определения проблемы в 4 в2784
Для выявления неполадок в 4 в2784 применяются различные подходы, направленные на детальную оценку функционирования системы. Ниже представлены наиболее распространенные методы диагностики.
| Метод | Описание | Применение |
|---|---|---|
| Логический анализ | Оценка логических структур и условий работы. | Определяет возможные сбои в алгоритмах. |
| Статический анализ | Проверка кода на наличие синтаксических ошибок и уязвимостей. | Используется для выявления некорректного кода до его выполнения. |
| Динамическое тестирование | Запуск программных модулей в контролируемом окружении. | Позволяет оценить поведение системы в реальных условиях. |
| Эмуляция | Создание виртуальной модели системы для анализа. | Целесообразно при отсутствии физического доступа к оборудованию. |
| Мониторинг | Непрерывная оценка работы системы в реальном времени. | Используется для выявления аномалий и сбоев в работе. |
Каждый из приведенных методов может быть использован в комбинации для достижения максимально точных результатов при диагностике. Эффективность обнаружения несоответствий значительно повышается при комплексном подходе, что позволяет быстро реагировать на возникающие проблемы и поддерживать стабильность системы. Регулярные проверки и тестирования снижают риски возникновения критических ситуаций.
Игнорирование проблемы и его последствия
Пренебрежение выявленной аномалией может привести к серьезным последствиям для функционирования системы. Первоначально, это сказывается на производительности: ускорение операций может быть нарушено, что затрудняет выполнение задач в запланированные сроки. Пользователи начинают сталкиваться с задержками при обработке данных, что затрагивает их продуктивность.
Экономический аспект также не следует упускать из виду. Увеличение времени простоя и количество неэффективно выполненных работ ведет к перерасходу ресурсов. В результате затраты на поддержку и обслуживание системы могут значительно возрасти, что отразится на прибыльности компании.
Каждое игнорирование приводит к ухудшению репутации, поскольку клиенты ожидают надежности и точности. Подобные сбои могут вызвать недовольство пользователей, что, в свою очередь, приведет к снижению клиентской базы. Инвестиции в восстановление имиджа могут стать дополнительной финансовой нагрузкой.
Необходимо также учитывать аспект безопасности. Нестабильные системы часто становятся уязвимыми для внешних атак. Это может привести к утечкам данных или их потере, что влечет за собой правовые последствия и негативные последствия для бизнеса.
Вместо игнорирования, следует сосредоточить усилия на исправлении проблемы. Регулярный мониторинг и анализ системы помогут выявить уязвимости, прежде чем они приведут к серьезным нарушениям. Внедрение проактивных мер снизит вероятность возникновения кризисных ситуаций и обеспечит стабильное функционирование организации.
Влияние недочётов на производительность системы
Наличие неточностей в коде может значительно снизить производительность системы. Различные аспекты, такие как скорость обработки данных и использование ресурсов, могут быть подвержены негативному влиянию. Лучшие практики программирования включают в себя тестирование и код-ревью для минимизации подобных проблем.
Технические последствия включают в себя увеличение задержек в работе приложений и снижение производительности серверов. Например, опечатки или неправильные расчёты могут привести к ошибкам в алгоритмах обработки данных, что замедляет их выполнение. Это также может вызвать увеличенное использование памяти и процессора, что, в свою очередь, снижает общую производительность системы.
| Проблема | Влияние на производительность |
|---|---|
| Ошибки в алгоритмах | Увеличение времени обработки |
| Неправильное использование ресурсов | Пиковое потребление памяти и CPU |
| Отсутствие оптимизации | Снижение скорости выполнения |
| Недостаточное тестирование | Непредсказуемое поведение приложения |
Для ??ения ситуации, следует внедрять автоматизированные инструменты для анализа кода и мониторинга производительности. Это поможет определить узкие места и минимизировать риски при разработке. Регулярные обновления и улучшения системы также способствуют повышению её производительности.
Рекомендации по устранению проблемы
Для минимизации негативного воздействия ошибки, связанной с возникшей ситуацией, рекомендуются следующие шаги:
1. Тщательный анализ кода: Необходимо провести детальный разбор кода, чтобы определить точное местоположение сбоя. Используйте средства отладки для выявления причин нештатной работы.
2. Проверка вводимых данных: Убедитесь, что все исходные данные соответствуют необходимым параметрам. Это поможет избежать некорректных значений и дальнейших сбоев в работе системы.
3. Логирование событий: Внедрите систему логирования для отслеживания действий программы. Это упростит выявление проблемных участков и позволит быстрее реагировать на неполадки.
4. Обновление зависимостей: Проверьте, не устарели ли используемые библиотечные компоненты. В случае необходимости обновите их до последних стабильных версий.
5. Создание резервных копий: Перед внесением изменений создавайте резервные копии важных данных. Это позволит избежать потерь в случае неудачного исправления.
6. Проведение тестирования: Необходимо тщательно протестировать исправленный код. Используйте юнит-тесты и интеграционные проверочные сценарии для гарантии стабильной работы системы.
7. Обратная связь: Если система используется другими пользователями, предоставьте им возможность сообщить о замеченных проблемах. Это поможет находить и устранять неисправности оперативно.
Следуя данным рекомендациям, можно существенно снизить вероятность возникновения ситуации в будущем и улучшить общую стабильность работы программы.
Профилактика повторного появления неисправностей
Для предотвращения повторных несправностей важно уделить внимание диагностики систем. Регулярное тестирование программного обеспечения и оборудования помогает выявить потенциальные уязвимости до того, как они приведут к сбоям. Кроме того, использование автоматизированных инструментов для мониторинга состояния компонентов системы позволяет быстро реагировать на изменения.
Модернизация систем и оборудования также играет значительную роль. Устаревшие компоненты и программы часто становятся причиной нестабильной работы, поэтому своевременное обновление до последних версий может снизить вероятность возникновения проблем.
Обучение персонала является неотъемлемой частью профилактических мер. Лица, ответственные за техническую поддержку и эксплуатацию систем, должны пройти специализированное обучение для правильного выявления и устранения проблем. Регулярные курсы и семинары помогут укрепить знания и навыки команды.
Введение системы резервного копирования данных и параметров конфигурации позволит избежать катастрофических последствий. Если сбой все же происходит, возможность быстрого восстановления сохранит рабочий процесс.
Фиксация информации о выявленных нарушениях и их исправлении в документации способствует созданию базы знаний для будущего. Анализ истории проблем может предоставить ценные сведения для предотвращения аналогичных случаев.
Соблюдение стандартов и регламентов в обслуживании оборудования улучшает стабильность работы систем. Регулярные инспекции и проверки помогают поддерживать высокие уровни обслуживания.
Анализ данных при возникновении ситуации
Когда происходит сбой в системе, важно провести детальный анализ собранной информации. Начать следует с определения масштабов проблемы: сколько пользователей было затронуто, каковы временные рамки инцидента и какие системы или компонентыFail-Over были задействованы.
Следующий шаг — сбор логов и записей. Необходимо обеспечить наличие данных о каждом шаге, который происходил в системе до возникновения сбоя. Это может включать запросы к базам данных, ошибки сервера и другие соответствующие журналы. Систематизация этой информации поможет выявить тренды и паттерны, которые могли привести к возникновению проблемы.
Для более глубокого анализа полезно использовать инструменты визуализации данных. Графики и таблицы помогут выявить корреляции и аномалии. Например, если наблюдается рост нагрузки на сервер до инцидента, стоит рассмотреть возможность переработки архитектуры или перераспределения ресурсов.
После того как данные собраны и проанализированы, важно разработать план действий. Указание на слабыe места архитектуры системы может помочь избежать повторного возникновения подобных ситуаций. Это может включать обновление программного обеспечения, изменения в конфигурации или улучшение мониторинга.
Регулярные тренировки по реагированию на сбои также способствуют повышению готовности команды. Создание сценариев и работу над ними можно инициировать в рамках обучающих семинаров для сотрудников. Это поможет отработать действия и сгладить потенциальные несоответствия в будущем.
Таким образом, системный подход к анализу информации позволяет не только быстро устранить недочеты, но и заранее минимизировать риски возникновения подобных сбоев. Контрмеры, основанные на полученных данных, постепенно формируют более надежную инфраструктуру.
Взаимосвязь с другими сбоями
Причина нештатной ситуации в одной системе часто укореняется в проблемах, связанных с другими компонентами. Необходимо понимать, как различные недоработки могут взаимосвязаться и усугубить общий перебой.
- Кросс-воздействие систем: Программные модули могут зависеть друг от друга. Повреждение в одном элементе может привести к сбоям в другом, усиливая общий эффект.
- Общие ресурсы: Использование одних и тех же баз данных и серваков может быть источником проблем. Перегрузка одного компонента может вызвать затруднения для всех остальных, снижающих производительность системы в целом.
- Неправильная конфигурация: Ошибки в настройках одного модуля могут иметь неочевидные последствия для других. Проверка всех конфигураций и их интеграции друг с другом поможет избежать недоразумений.
Рекомендуется регулярно проводить аудит всех взаимосвязей в системе. Это позволит выявить потенциальные слабые места и снизить риски.
- Проводить тестирование взаимодействий всех компонентов на предмет уязвимостей.
- Мониторить загрузку ресурсов, чтобы предотвратить чрезмерную нагрузку на ключевые элементы.
- Обновлять программное обеспечение, обеспечивая совместимость различных модулей.
Внимание к взаимозависимостям компонентов системы является залогом стабильности и надёжности работы в целом.
Кейс-стадии с реальными примерами неудач
В большинстве случаев неудачи происходят из-за недостаточной проработки деталей. Примеры из практики показывают, насколько подобные упущения могут вызвать масштабные проблемы.
-
Проект ‘Альфа’: Это начинание в области финансовой аналитики столкнулось с сильной критикой после того, как была запущена система обработки данных. Изначально недооценили объем информации, и в результате пользователи столкнулись с серьезными задержками и сбоями. Итог – значительное ухудшение репутации компании.
-
Кампания ‘Бета’: Программа маркетинга для нового продукта не справилась с требованиями рынка. Не было проведено должного анализа целевой аудитории, что привело к игнорированию предпочтений потребителей. В итоге продаж оказалось недостаточно для рентабельности проекта.
-
Инициатива ‘Гамма’: Внедрение новой IT-системы не предвещало проблем. Однако, недостаточная подготовка пользователей привела к низкой адаптации. Бюджет был перерасходован на обучение, в то время как эффективность снижения затрат не была достигнута.
Эти примеры демонстрируют, как малейшие неточности могут привести к значительным затратам времени и ресурсов. Что можно извлечь из этих ситуаций?
- Проведение глубокого анализа потребностей всех заинтересованных сторон перед запуском.
- Тестирование невидимых аспектов системы на этапе разработки, чтобы минимизировать возможные трудности.
- Обучение сотрудников и подготовка их к использованию новых инструментов должны быть обязательными.
- Регулярная обратная связь от пользователей для корректировки текущих процессов на ранних этапах.
Внимание к деталям и тщательное планирование являются сильными сторонами успешных проектов. Бездействие в этих аспектах может обернуться потерей не только времени, но и ресурсов и доверия клиентов.